The benefits of open-source AI: open-source supports novel research
In this fourth blogpost about the benefits of open-source AI, we discuss how open-source supports novel research. We outline the research value inherent to publicizing models in a fully open and reproducible manner, and provide examples of the open-source AI community building off earlier work to further academic progress.
Information dissemination
By our standards, open-source AI models must comprehensively document the techniques used when developing their models, preferably in peer-reviewed papers. This encourages a broad dissemination of AI knowledge which strengthens the entire AI space, and allows others to easily adopt innovations. In contrast, obfuscating key parts of one's research or even avoiding discussing key techniques used entirely leads to a research environment with a large amount of uncertainty as to what the cause of an innovation even is.
For an example of openness enabling further research, we turn somewhat counterintuitively to DeepSeek. In the wake of DeepSeek's release, many model creators started to look at its theoretical background to see how it achieved its state-of-the art performance. One innovation employed by DeepSeek was GRPO, a reinforcement learning technique especially suited for teaching reasoning. Despite some other innovations of the model being somewhat obscured (e.g. its high-quality dataset), this technique was published in such a way that it could be easily adopted in other models. For a very rough measure of the speed of adoption, the following graph shows the frequency of the term 'GRPO' in arXiv papers, usually one of the first spots for model creators to publish the scientific background of their models:
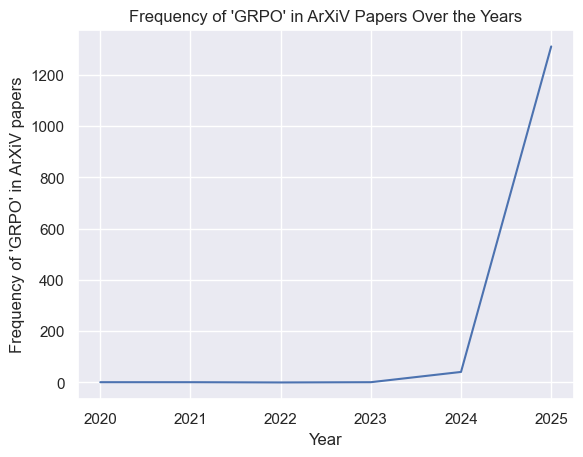
Indeed, once a model has demonstrated the efficacy of an innovation, the AI research community is blisteringly quick to adopt it.
Datasets and checkpoints
A key part of research-relevant information which is often overlooked is the data used to train a model. Sharing data and data collection strategies allows for insight into how to construct the enormous datasets necessary for training state-of-the-art models, and existing datasets can easily be used or adapted to develop more models. Publishing model checkpoints in addition to a base dataset further allows for the full reproducibility of the model in a verifiable manner, as well as experiments relating to the evolution of the model.
Conclusion
In these ways, open-source model development furthers research goals significantly. By publishing their research findings in an open manner, developers can ensure that others can easily benefit from innovations made. And through the sharing of data and possibly even model checkpoints, developers make it much easier to both develop subsequent models and tinker with existing ones. In short, by striving for maximal open-source status, institutions can effectively accelerate research progress on AI for all.