In the past few weeks, the DeepSeek model family has attracted a great deal of attention. Their own release claims superior performance to GPT-4o while having been trained at a fraction of the cost and with great efficiency. Claims of "open source" status are a prominent part of its appeal. In this post, we dive into the development history of DeepSeek and investigate its place in the larger open-source landscape.
TL;DR: DeepSeek represents interesting technical developments, but it is at best "open weights", not open source: crucial elements of the training process, pre-training data and instruction-tuning data remain behind closed doors. In our openness index, DeepSeek's models end up somewhere in the middle of the pack: more open than some big name rivals, but too closed to enable serious auditing or scientific scrutiny. Read on for details.
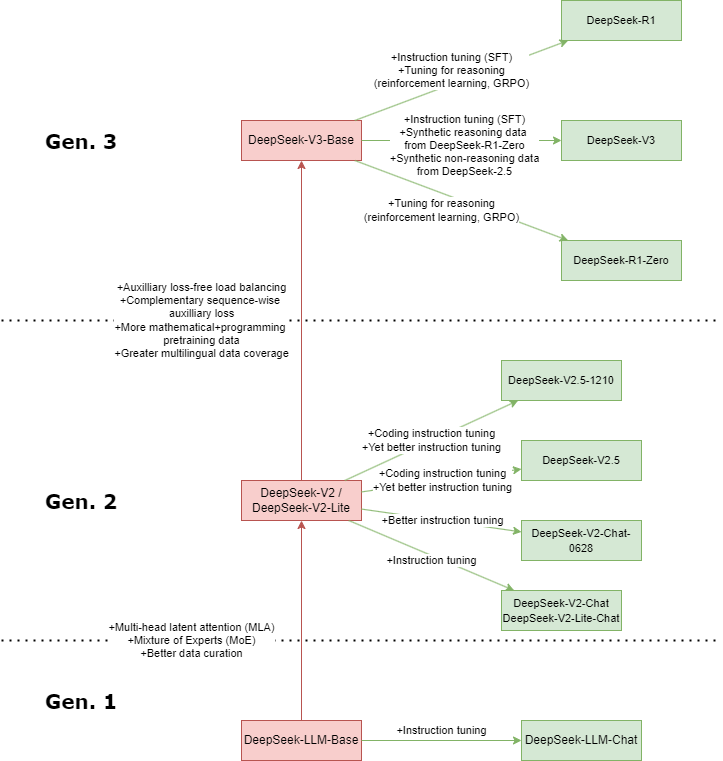
The development of DeepSeek can be visually depicted as follows:
The first generation of the DeepSeek models (DeepSeek-LLM-Base and DeepSeek-LLM-Chat) used a relatively straightforward recipe. A base LLM was trained using a large amount of data (at least CommonCrawl, a project which archives most of the public-facing internet), and the model was subsequently fine-tuned to work well as a chat model using a combination of supervised fine-tuning (SFT) and direct preference optimization (DPO). DeepSeek technical reports place a strong emphasis on the importance of data filtering, keeping only the most essential and highest-quality data to learn from. The largest of the first generation base models claimed superior performance to Llama-2-70B across a range of benchmarks, and the chat model even claimed superior performance to GPT-3.5.
DeepSeek-V2 departed from this recipe by adopting a mixture-of-experts (MoE) approach, an approach first popularized by Mixtral. In this approach, many models are trained in parallel to each specialize in a specific knowledge domain ('expert models'). When generating text the overarching 'parent' model then switches between which expert it uses to generate text depending on the context. The DeepSeek team trained a single mixture-of-experts 'base' model using curated data, and subsequently experimented with what data would work best for fine-tuning it by constructing several generations of chat models. A key discovery during this stage was that integrating data used for code-tuning a model (optimizing it to generate code well) seemed to improve performance measures in both chat and code settings. Models integrating both code and regular instruction data were referred to as DeepSeek-V2.5.
The third generation of DeepSeek built on this same approach while using more and better data. The model was scaled up to three times the size of DeepSeek-V2, and for training an increased amount of mathematics, programming, and multilingual data was incorporated. The model also integrated some novel techniques to better balance the different experts between each other. This third-generation model is the base of three offshoots: DeepSeek-R1-Zero, Deepseek-V3, and DeepSeek-R1.
For DeepSeek-R1-Zero, the DeepSeek team first attempted to use a novel reinforcement learning technique (GRPO) to endow the base model with a greater understanding of reasoning. This technique was already used with success in the mathematically-tuned cousins of DeepSeek in order to provide mathematical reasoning, and so the step towards using it to endow a model with general reasoning capabilities appears logical. Although DeepSeek-R1-Zero seemed to display better reasoning capabilities, the technique used also resulted in quite a few instabilities in how the model behaved. The model was prone to switching between languages, not adhering to formats, and in general providing poorly-readable responses. Nonetheless, the experiment evidently proved valuable for subsequent development.
The next publicly-released fine-tuning attempt was DeepSeek-V3. This model experimented with using synthetic data (data generated by a different LLM) to better learn how to serve as a chat-bot. It used filtered output from both DeepSeek-R1-Zero and DeepSeek-V2.5 to learn how to perform both reasoning and non-reasoning tasks well. Fine-tuning is commonly said to require far less compute than pre-training, and the same held here. The model was fully fine-tuned using only 1.5 million `instances' of instructions to learn from (these instructions are not made available). Though the performance of this model was quite promising, development continued.
DeepSeek R1 was the third fine-tuning attempt, and this ended up drawing most attention. The key idea here was to take the approach used to train DeepSeek-R1-Zero while prepending a small phase of `traditional' instruct-tuning in an attempt to resolve the observed instabilities. This turned out to indeed be the case. DeepSeek's own technical reports claim that performance of this model rivals GPT-4o.
The term "open source" gets bandied about a lot in the current Generative AI landscape, often in the service of open-washing: projecting an image of transparency without doing much of the work required to count as meaningfully open. How does DeepSeek fare in this respect? Knowing this is important because it determines how others can audit, trust, scrutinize, and build on its models.
For a first quick impression, let's compare DeepSeek to two other well-known models: OLMO 7B and Llama. As is clear from this comparison, DeepSeek is a little more open than Llama (mainly on account of providing easier access to model weights and an API), but does not come close to the degree of openness of the current open source industry standard: AllenAI's OLMO. Read on to see the elements of openness that enter into this comparison.
Parameter descriptions:
Base Model Data
Are datasources for training the base model comprehensively documented and made available? In case a distinction between base (foundation) and end (user) model is not applicable, this mirrors the end model data entries.
End User Model Data
Are datasources for training the model that the end user interacts with comprehensively documented and made available?
Base Model Weights
Are the weights of the base models made freely available? In case a distinction between base (foundation) and end (user) model is not applicable, this mirrors the end model data entries.
End User Model Weights
Are the weights of the model that the end user interacts with made freely available?
Training Code
Is the source code of dataset processing, model training and tuning comprehensively made available?
Code Documentation
Is the source code of datasource processing, model training and tuning comprehensively documented?
Hardware Architecture
Is the hardware architecture used for datasource processing and model training comprehensively documented?
Preprint
Are archived preprint(s) are available that detail all major parts of the system including datasource processing, model training and tuning steps?
Paper
Are peer-reviewed scientific publications available that detail all major parts of the system including datasource processing, model training and tuning steps?
Modelcard
Is a model card available in standardized format that provides comprehensive insight on model architecture, training, fine-tuning, and evaluation?
Datasheet
Is a datasheet as defined in "Datasheets for Datasets" (Gebru et al. 2021) available?
Package
Is a packaged release of the model available on a software repository (e.g. a Python Package Index, Homebrew)?
API and Meta Prompts
Is an API available that provides unrestricted access to the model (other than security and CDN restrictions)? If applicable, this entry also collects information on the use and availability of meta prompts.
Licenses
Is the project fully covered by Open Source Initiative (OSI)-approved licenses, including all data sources and training pipeline code?
For both training and chat-tuning, DeepSeek makes use of a proprietary dataset that is not disclosed. Though the paper of the original DeepSeek-LLM suggests that this data is primarily obtained from the CommonCrawl, a lack of transparancy of how and what data is gathered means that the exact data mixture is unknown. Methods for deduplicating and curating the data are described in earlier papers, however in too abstract terms to enable accurate reproduction.
It could be that this is a deliberate strategy on the part of DeepSeek, as it seems that their primary strategic advantage lies in their highly curated and high-quality dataset. By not publishing it, they are free to publish the techniques involved in training their models without having to worry about a superior-performance competitor emerging in the near future. In any case, further insight is warranted into the datasets used in training DeepSeek.
DeepSeek publishes both the base and the end model weights of all of their chat-tuned models. This allows for researchers to use these models as a foundation to fine-tune their own LLMs. However, merely publishing the weights of a model is not sufficient for it to be considered truly open-source. In fact, model weights are "the most inscrutable portion" 1 of a generative AI system, and they cannot be meaningfully inspected, understood or tinkered with in the absence of open data and code.
We find that training and fine-tuning code is quite sparse overall and certainly not sufficient to replicate the training process of any of these models. The repository of the base model DeepSeek-V3-Base contains very limited code for building on the model; such code is not available for DeepSeek-R1. In general, the DeepSeek team is not very forthcoming when it comes to publishing the code used to train their model. In the repository for DeepSeek-V3-Base they provide code for loading and quantizing the model, not much else. This leaves the development process quite obscured and clashes directly with the claimed "open source" status. The source of DeepSeek is not open.
Given the limited extent to which code was published for DeepSeek, the documentation of this code is also very limited. The architecture, however, is documented a lot better. It is described in considerable detail in multiple technical reports published by the DeepSeek team on GitHub. This documentation provides some insight into the model architecture and is the main source for some of the reporting on technical innovations.
The technical reports for DeepSeek models are more detailed than those of several other model providers. However, without corresponding code and training data, it is impossible to verify any of the claims made in these reports. None of them have undergone scientific scrutiny in the form of peer review or independent auditing. DeepSeek is far from alone in making this choice; indeed glossy technical reports have become standard fare in the generative AI landscape. This is another sense in which the work is less than fully open.
Model cards and data sheet represent standardized ways for reporting key aspects of model architecture, use cases, limitations, and biases. DeepSeek comes with a model card that is only partly filled out. In particular, it lacks a risk assessment, a discussion of limitations of the model, and a description of biases the makers are aware of. Given that no source data has been published, no data sheet has been released either, which is another sense in which DeepSeek's model are less than fully open.
DeepSeek-R1 integrates well with many widely-used packages. An API is also available, and an app has been published which allows users to try out the model with a very low barrier of entry. The openly available model weights also mean that advanced users can run DeepSeek models locally, though this will in most cases require specialized hardware owing to the size of the model.
As for licensing, part of the code is released under a standard MIT software license, while the weights are released under a custom DeepSeek Model License, the open-source status of which is in doubt. A surface-level read suggests that the license is not overly restrictive, but greater scrutiny is by legal experts is required.
DeepSeek's popularity is due to the coupling of remarkable performance and wide availability. However, nominally free availability should not be confused with "open source". DeepSeek is highly similar to Meta's Llama in terms of the release strategy and the strategic appropriation of the term "open source" (though it is marginally more open on some dimensions). For both model families, key aspects of training data and model development are strategically obscured.
DeepSeek's claim to openness appears to be to an attempt to align with other open-weights models more than a true signal of open source status. The technical advances of DeepSeek rightly arouse a lot of interest, but only meaningful openness of training data and code will make it possible for anyone to assess claims of superior performance and advance truly open generative AI.